Python
Python
Python基础
解释器与编译器
解释器输出运行的结果
编译器输出编译的文件
字面量:写在代码中的值,可以被分为整数,浮点数,字符串,元组,列表等
python的单引号和双引号意义相同,但是使用单引号可以打出双引号,但不能打出单引号。使用双引号则反之,如果想使用单引号打出单引号,则需要加上反斜杠代表转义字符
注释的写法
1 | # 这是单行注释 |
python中变量无类型而数据有类型,可以通过type(数据)来查看数据拥有的数据类型,同时也可以使用type(变量)来查看变量拥有的数据类型
类型转换
1 | int(x) # 将x转换为int类型 |
float转换为int会丢失精度
python舍弃精度时是四舍五入
运算符
1 | print(9//4) # 结果为2 |
字符串可以通过转义字符来包含引号
拼接
1 | # 可以进行字符串之间的拼接,也可以进行字面量和变量之间的拼接 |
占位符与格式化
1 | birth = 2001 |
输入函数
1 | input("提示语") # input得到的数据永远是字符串类型 |
循环语句
1 | while condition: |
:::alert-info
for循环里的临时变量会自动自增,但是while需要手动自增
:::
range
1 | range(num) # 获得一个从0开始不含num的数字序列,例如range(5),获得一个0,1,2,3,4的序列 |
函数
1 | def functionname(parameter) |
函数无返回值,返回的是None
对于一些不想要设置初始值而需要定义的变量来说,可以先让这个变量赋值为None
函数作为参数传递
1 | def fun1(fun): |
数据容器
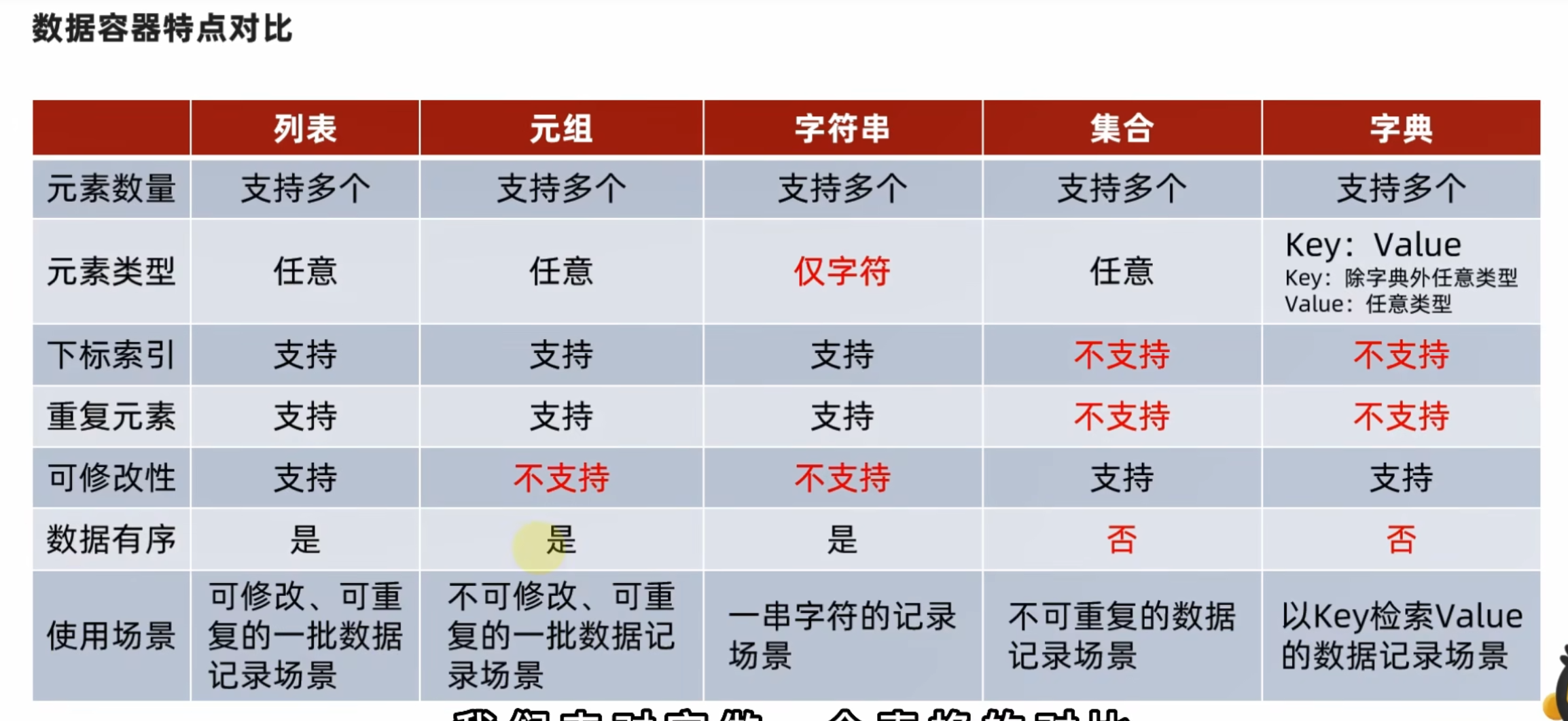

数据容器的转换
其他数据容器不能转换为字典
1 | # 将其他数据容器转换为列表 |
列表(list)
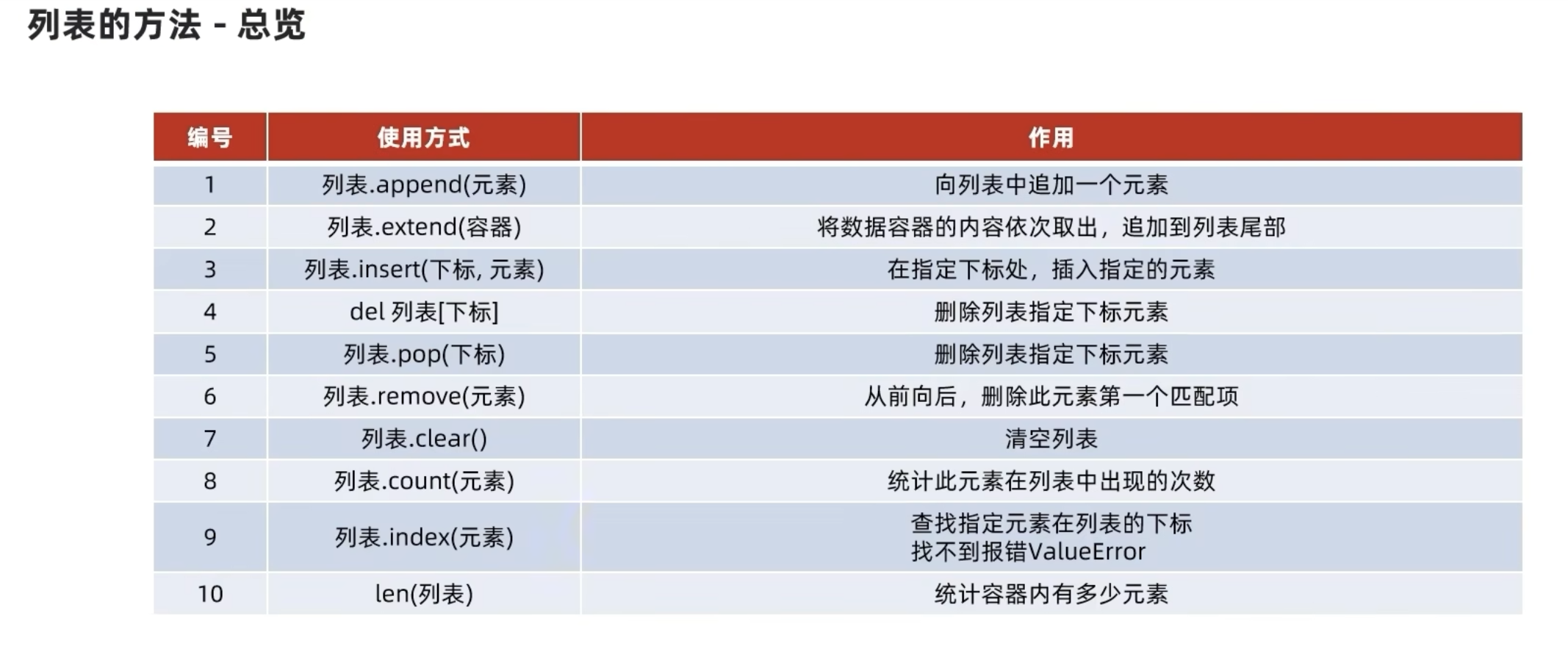
列表可以存储不同数据类型的元素,并按照一定下标排序,允许重复数据存在
1 | # 列表的字面量定义 |
嵌套列表获取元素list_name[0][1]
将函数定义为类中的成员,我们称这种函数叫做方法
1 | #查询元素 |
元组(tuple)
元组一旦定义好,内部的元素就不可修改。但如果元组内嵌套了list,则可以修改list的内容,可以将元组视为不可修改元素的list
元组内部数据类型可以不同
1 | # 定义元组字面量 |
字符串(str)
字符串是一个不可修改的数据容器
1 | my_str = "hellow world" |
序列
序列是指内容连续,有序,可使用下标索引的一类数据容器
1 | # 语法 |
集合(set)
集合内元素不能重复且无序,但允许修改
因为集合不支持下标索引,所以不支持while循环,但支持for循环
1 | # 定义集合字面量 |
字典(dict)
字典无序没有索引,只能通过Key值找到对应的value
字典的Key不可重复
字典的Key和value可以为任意数据类型(但Key不可为字典)
1 | # 字典的定义 |
函数进阶
多返回值函数
1 | def fun_name(): |
- 函数参数种类:
- 位置参数 fun_name(“小明”,10,”男”)
- 关键字参数 fun_name(name = “小明”,gender = “男”,age = 10),顺序可以调换,但与位置参数混用时,需要放在位置参数后面
- 缺省参数 函数定义时在参数列表中给参数赋值即可指定缺省参数,设置缺省参数时,设置的参数要放在参数列表最后,否则会报错
- 不定长参数
- 位置参数的形式:fun_name(*args),传参示例:
10,20,30会将传进去的参数合并成一个元组 - 关键字传递的形式:fun_name(**kwargs),传参示例:
age = 10,gender = male会将传进去的参数合并成一个字典 kwargs(key word args)
- 位置参数的形式:fun_name(*args),传参示例:
lambda函数
lambda函数是一种临时函数,使用一次后就被销毁了,下次使用只能再次重写lambda函数并且lambda函数只能写一行
lambda函数语法:lambda 参数 : 函数体
1 | def test_fun(compete): |
异常
异常的捕获
1 | try: |
异常的传递
异常可以根据函数调用呈现传递性

模块
模块就是一个python文件,可以将模块视作功能包
不同的模块,相同名称的功能,后导入进来的会覆盖先导入进来的
[]代表可选的意思
1 | # 只使用import会将模块中所有内容全部导入,而使用from则会将模块中的某一部分导入 |
包
python包 = __init__.py + 若干模块文件
可以在 __init__.py文件内添加 __all__ = [“模块名”]来定义 from package import * 的导入范围

面向对象
类的定义
1 | class 类名称: |
构造方法
构造方法需要使用__init__()方法,与C++构造函数类似,即使不给出__init__()方法,系统也会自动调用
类进行初始化的时候会首先调用__init__()方法,,这个函数可以初始化类的成员变量
1 | class student: |
魔术方法
python中,由两个下划线前后包围起来的方法称为魔术方法
定义__str__方法后,以后将类转换为字符串就会输出__str__方法中的内容
__lt__,__le__,__eq__是比较两个类大小的魔术方法,由于两个类不能比较,所以需要在这三种方法内部重写比较方法,一般比较的是两个类中成员的大小
封装
在成员或者方法前加两个下划线即可将成员或方法变为私有
1 | class student: |
继承
class 类名(父类名):
类的内容
想要继承多个父类时使用:
class 类名(父类1,父类2,父类3):
类的内容
如果只想继承若干个父类,而不想写类的内容,可以使用pass关键字,以补全类的内容
class 类名(父类1,父类2,父类3):
pass
当父类1与父类2中有同名的成员变量或成员方法时,优先继承父类1的内容,遵循先来后到原则
1 | class student: |
当需要对父类的成员变量或者成员方法进行改动时,可以在子类中重新定义,以达到复写的效果
1 | class student: |
多态
多态:同一个函数,使用不同的对象,产生不同的结果
通过多子类父类以及继承方式可以实现多态,例如
- 定义空调父类,定义空调的制冷方法
- 定义格力空调,美的空调子类,并在其内部重写制冷方法
- 实现通用制冷函数,可以调用传进来的类的方法
- 在制冷函数内传入美的或者格力空调子类,这样就实现了多态现象
此时父类称为抽象类或接口,只做大体框架或者顶层实现

闭包
闭包的好处是可以将外层函数的变量置于函数内部,这样可以防止其他函数或操作修改外层函数的变量,使程序更安全。但同时内部函数会持续引用外部函数的值,增大了内存的开销
1 | def outer(add): |

装饰器
装饰器是闭包的一种特殊用法,他将闭包中的全局变量改为函数,可以增加原函数的功能,并支持语法糖
1 | #############普通的装饰器########## |
迭代器
迭代是 Python 最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
1 | #!/usr/bin/python3 |
输出结果:
1 | 1 2 3 4 |
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__()
__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成
__next__() 方法(Python 2 里是 next())会返回下一个迭代器对象
1 | class MyNumbers: |
输出结果:
1 | 1 |
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator),生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果.跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器
当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后面的表达式作为当前迭代的值返回。然后,每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。这样可以不必一次生成大量数据,从而节省内存空间
1 | def countdown(n): |
生成器实现fibonacci数列
1 | #!/usr/bin/python3 |
输出结果:
1 | 0 1 1 2 3 5 8 13 21 34 55 |
设计模式
单例模式
类的实例化只进行一次,以后均使用这个实例化的类,这样可以节省内存,多用于工具类的创建
工厂模式
将杂散的对象由某个类统一创建,这样可以方便统一管理杂散的数据,并且当其中的数据进行重新赋值时,只进行类内部重新赋值即可而不需要找到每处实例化的对象